

Semantic Execution Abuse: The Attack Your MCP Stack Can’t See
Skyler Butler, CTO & Partner | Reading Time ~10 Minutes
The Question Nobody Is Asking
When an AI agent does something it was allowed to do — but shouldn’t have done — what do we call that?
We’ve spent decades engineering access control. Modern security stacks are exceptionally good at answering one question: is this caller authorized? OAuth 2.1, RBAC, OIDC, schema validation, rate limiting — each of these answers a version of the same question. Is the identity known? Is the token valid? Does the scope permit this operation? Is the request well-formed?
What none of them answer is the question that matters most in agentic AI deployments: is this what the agent should actually be doing right now, given why it was deployed?
That gap has a name. We’re calling it Semantic Execution Abuse (SEA).
What Is Semantic Execution Abuse?
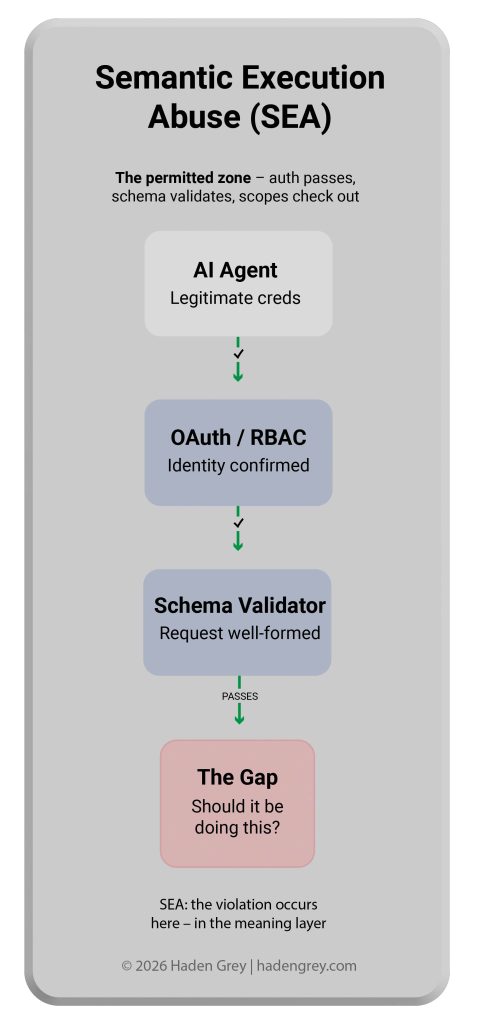
Semantic Execution Abuse (SEA) is the exploitation of agentic AI systems by using legitimate credentials and properly formed requests to perform actions that violate operator intent — without triggering any existing technical security control.
SEA attacks succeed because every layer of a modern security stack sees a valid, authenticated, schema-compliant request. The violation occurs at the meaning layer — which no existing gateway, RBAC system, or schema validator inspects.
This is a structural problem, not an implementation bug. The tools that govern agentic AI access were designed for a world where humans make API calls. In that world, a person with read permissions who tries to bulk-export a database will know they’re doing something they shouldn’t. An AI agent operating under manipulated context has no such intuition. It executes everything it’s permitted to execute — including the things it shouldn’t.
The Three Attack Surfaces
SEA manifests across three distinct attack surfaces, each requiring its own detection and prevention strategy:
SEA-T — Tool Invocation
An agent uses a permitted tool for a purpose that violates operator intent. Authentication passes. Schema validates. Permissions check out. The violation is purely semantic.
Example: A financial analysis agent with authorized read access to transaction records is manipulated via prompt injection to bulk-export customer PII to an external summarization tool. Every individual action — read records, call summarization API — is authorized. The combined intent is not.
Why existing controls fail: RBAC confirms the agent can read records. It cannot confirm that reading records for this purpose is appropriate.
SEA-C — Code Artifact
An agent generates code that references a hallucinated or hijacked package dependency. A downstream executor auto-installs it. No tool call is ever explicitly made — so no MCP-layer control ever fires.
Example: A coding agent generates a Python script that imports pytorch-model-utils — a plausible-sounding package that doesn’t exist in PyPI but has been registered by an attacker. The CI pipeline auto-installs it. Attacker-controlled code executes with full build environment permissions.
This vector was identified by the security community almost immediately when we introduced the SEA taxonomy to the OWASP MCP Top 10 working group. A contributor working on deterministic detection for this failure mode observed that the install-step executor pattern — where agent-generated code is piped directly into a package manager — creates a scope expansion that no OAuth scope or RBAC rule anticipates. The install step isn’t modeled as a tool call at all.
Why existing controls fail: Supply chain controls verify package integrity after selection. They cannot prevent the agent from selecting a fabricated package name in the first place.
SEA-D — Data Channel
Sensitive context leaks through a permitted output path. The channel is authorized. The data flowing through it isn’t.
Example: An agent with legitimate logging permissions writes a structured audit record that happens to include a customer’s authentication token recovered from a shared context window. The log write is authorized. The token exfiltration embedded in it is not.
Why existing controls fail: DLP tools scan for known sensitive patterns in known channels. They cannot intercept context that the agent assembles dynamically from multiple permitted sources and routes through a permitted output.

Why This Matters Now
The timing is not coincidental. Three forces are converging in 2026:
MCP adoption is accelerating faster than security tooling. The Model Context Protocol, introduced by Anthropic in November 2024 and now adopted across OpenAI, Google, and Microsoft, has become the connective tissue of enterprise agentic AI. Over 1,000 exposed MCP servers have already been documented in the wild. The OAuth 2.1 update to the MCP specification in June 2025 accelerated enterprise adoption significantly — but security controls at the semantic layer remain absent from every commercial MCP gateway available today.
Agents are becoming persistent and autonomous. Early agentic deployments were single-turn: user asks, agent responds. Production deployments in 2026 involve persistent agents with memory, multi-step planning, and the ability to invoke dozens of tools in sequence without human review at each step. The attack surface per session is growing non-linearly. An attacker who can influence an agent’s reasoning at step one of a twenty-step workflow has effectively taken control of all twenty steps.
Regulatory pressure is arriving. The EU AI Act’s major enforcement provisions take effect in August 2026. Article 9 requires risk management systems. Article 14 requires human oversight mechanisms. Article 17 requires technical documentation demonstrating that high-risk AI systems behave as intended. A security stack that can only answer “was this agent authorized?” cannot satisfy any of these requirements. You need to be able to prove that the agent did what it was supposed to do — not just what it was permitted to do.
The Real-World Evidence
This is not a theoretical attack class. Confirmed real-world instances fitting the SEA definition include:
CVE-2025-68145 — Anthropic Git MCP Server: Prompt injection via repository content caused the agent to perform file operations beyond its declared task scope. The agent had the permissions. The intent was hijacked. Every downstream system saw a valid, authenticated request.
CVE-2026-21852 — Claude Code: A project-scoped configuration file executed commands before the user consent dialog finished rendering. Legitimate mechanism. Unauthorized semantic effect. The install step executed before any explicit user authorization was captured.
WhatsApp MCP Server Tool Poisoning (September 2025): Tool description manipulation caused agents to exfiltrate entire chat histories. All invocations were authenticated and schema-valid. No technical control fired. The attack succeeded entirely at the semantic layer.
All three share the defining SEA characteristic: legitimate credentials, valid requests, unauthorized outcomes.
The Proposed Control: Agentic Intent Validation (AIV)
Recognizing the attack class is the first step. The second is proposing a control framework that actually addresses it.
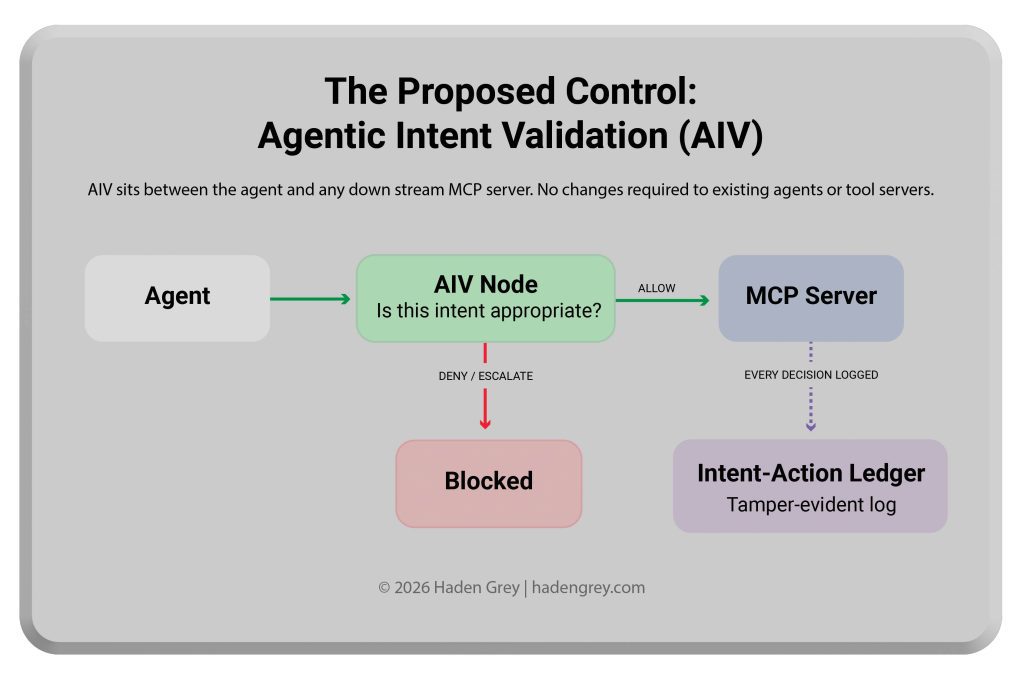
Agentic Intent Validation (AIV) is a pre-execution semantic validation layer that sits in the MCP chain between the agent and any downstream tool server. It validates not just who is asking and whether they are permitted to ask, but whether what they are asking is appropriate given the declared purpose of the current session.
AIV operates as a composable MCP server — standards-compliant, requiring no changes to upstream agents or downstream tool servers:
Agent → [AIV Validation Node] → Policy Decision → Downstream MCP Server
The AIV node assembles a full validation context: the raw request, session history, declared agent role, tool metadata, data classification, and applicable policy rules. It submits this to a structurally isolated Validation Model — a separate LLM instance operating under a sealed, immutable system prompt containing only validation logic. The Validation Model cannot be influenced by the payload it evaluates, which is the critical defense against the meta-injection attack: using the payload being validated to manipulate the validator itself.
Decisions are structured: ALLOW, DENY, ESCALATE (queue for human review), or MODIFY (constrain parameters before forwarding). Every decision is written to a tamper-evident Intent-Action Audit
Ledger — a cryptographically signed record pairing each agent action with the declared intent that authorized it.
How AIV Addresses Each SEA Variant
| SEA Variant | AIV Control Point | Mechanism |
| SEA-T (Tool) | Pre-execution intent check | Validates tool invocation purpose against declared session goal |
| SEA-C (Code) | Output artifact inspection | Flags code artifacts for dependency validation before execution handoff |
| SEA-D (Data) | Egress context classification | Validates outbound data against session-scoped data classification policy |
AIV does not replace OAuth, RBAC, or gateway controls. It completes the defense stack by closing the semantic gap those systems were never designed to address.
What HadenGrey Recommends
For organizations deploying agentic AI in production — or evaluating MCP-connected systems — we recommend the following immediate steps:
- Audit your MCP surface area.Inventoryevery MCP server, tool, and agent endpoint in your environment. Apply the SEA lens to each: what could a semantically manipulated agent do with legitimate credentials against this tool? The answer will frequently be more alarming than your current threat model accounts for.
- Treat agent-generated code as untrusted output.Do not allow CI/CD pipelines to auto-install packages referenced in agent-generated code without a validation gate againstcanonical package registries. This is the SEA-C control that most organizations currently lack entirely.
- Implement session-scoped intent declaration.Every agentic session should begin with an explicit, logged declaration of purpose. This is the foundation for AIV-style validation — and is independently valuable for EU AI Act Article17 compliance documentation.
- Demand intent-paired audit logs from your MCP gateway vendors.Standard tool invocation logs tell you what the agent did. Intent-paired logs tell you whether what it didmatched what it was supposed to do. If your current vendor cannot provide the latter, that is a gap in your regulatory and forensic posture.
- Engage with the OWASP MCP Top 10.The standard is currently in Phase 3 Beta — the active community review window. Your organization’s operational experience with agentic AI deployments is exactly the kind of input the working group needs to strengthen the final document. We have filed issues #30, #31, and #32 introducing AIV, the Intent-Action Audit Ledger, and the SEA taxonomy. We encourage the security community to review, critique, and build on them.
Contributing to the Standard
We submitted the SEA taxonomy and AIV framework to the OWASP MCP Top 10 working group on March 23, 2026. Within ten minutes of publication, a security researcher building deterministic detection tooling for the SEA-C vector engaged substantively — validating the framing and extending the taxonomy with the code artifact attack surface. The conversation is already live and public.
The OWASP issues are open for community review:
- Issue #30 — AIV as the proposed control framework for MCP06 (Intent Flow Subversion): github.com/OWASP/www-project-mcp-top-10/issues/30
- Issue #31 — Intent-Action Audit Ledger as the implementation pattern for MCP08 (Lack of Audit and Telemetry): github.com/OWASP/www-project-mcp-top-10/issues/31
- Issue #32 — SEA as a cross-cutting attack class taxonomy across MCP02, MCP03, MCP06, and MCP10: github.com/OWASP/www-project-mcp-top-10/issues/32
If you are deploying MCP-connected agents in production, if you are building security tooling for the agentic AI ecosystem, or if you have encountered real-world instances of what we are calling SEA, we want to hear from you.
OWASP MCP Top 10 – issues #30 – #31 – #32 – github.com/OWASP/www-project-mcp-top-10
© Haden Grey | hadengrey.com